在Python中,可以使用re模块(正则表达式模块)进行字符串匹配。re模块提供了一系列功能强大的函数来处理字符串,例如查找、替换和分割等。

以下是使用re模块进行字符串匹配的一些基本示例:
导入re模块:
python
代码
import re
匹配字符串:
使用re.match()函数可以在字符串的开头进行匹配。如果匹配成功,返回一个匹配对象;否则,返回None。
python
代码
import re
pattern = r"hello"
string = "hello, world!"
match = re.match(pattern, string)
if match:
print("Match found:", match.group())
else:
print("No match found")
搜索字符串:
使用re.search()函数可以在整个字符串中搜索匹配的模式。如果找到匹配,返回第一个匹配对象;否则,返回None。
python
代码
import re
pattern = r"world"
string = "hello, world!"
match = re.search(pattern, string)
if match:
print("Match found:", match.group())
else:
print("No match found")
查找所有匹配:
使用re.findall()函数可以找到所有匹配的子字符串。返回一个包含所有匹配子字符串的列表。
python
代码
import re
pattern = r"\d+"
string = "There are 3 cats and 4 dogs."
matches = re.findall(pattern, string)
print("Matches found:", matches)
替换字符串:
使用re.sub()函数可以替换匹配的子字符串。返回替换后的新字符串。
python
代码
import re
pattern = r"\s+"
string = "Replace all spaces with a single space."
result = re.sub(pattern, " ", string)
print("Result:", result)
要使用re模块进行字符串匹配,您需要熟悉正则表达式的语法。正则表达式是一种用于描述字符串模式的强大语言,可以匹配复杂的文本结构。学习正则表达式可以帮助您更有效地处理字符串和文本数据。
以下是一些正则表达式的基本语法和示例,以帮助您更好地理解如何在Python中使用正则表达式进行字符串匹配:
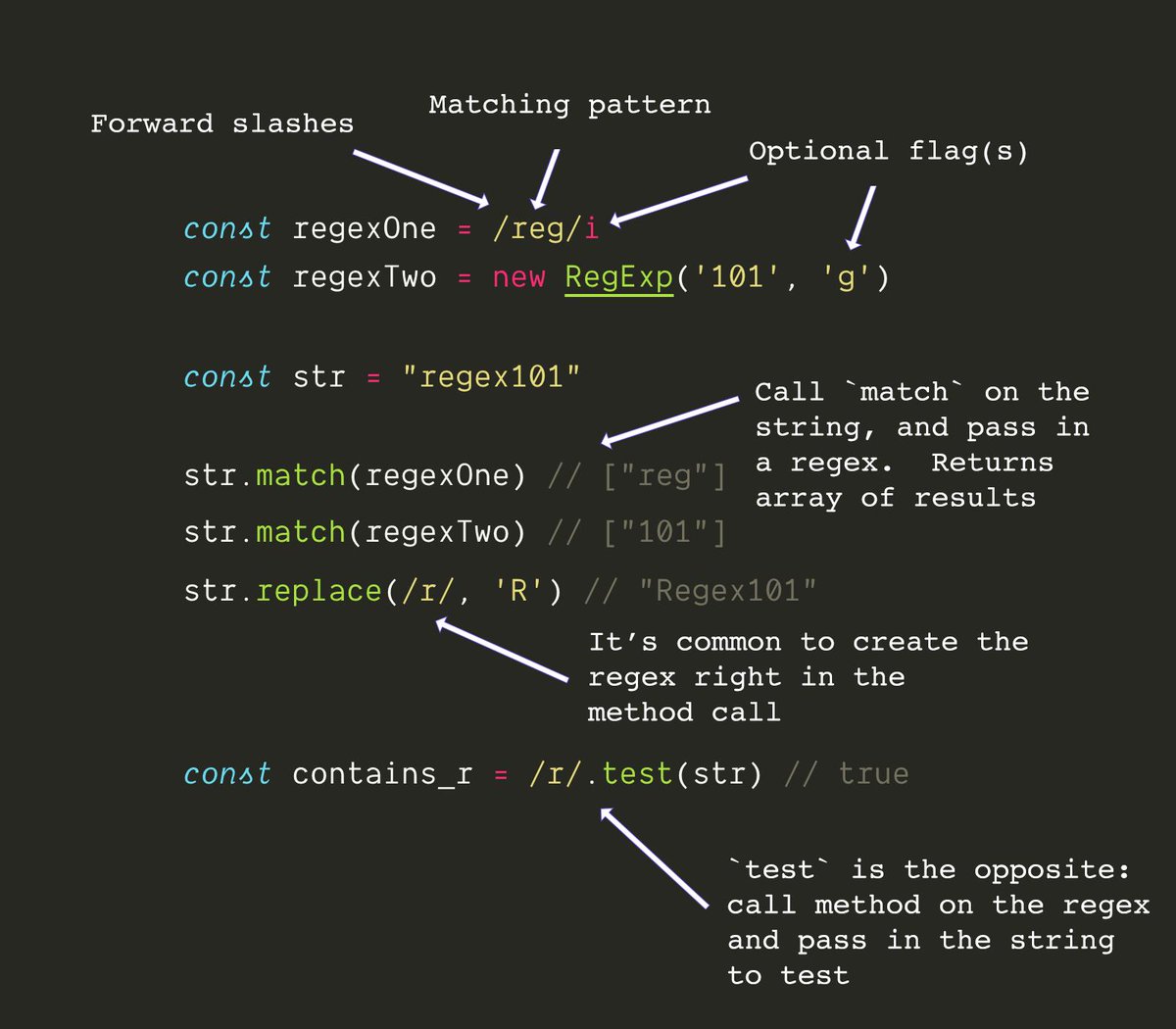
特殊字符:
.:匹配任意单个字符(除换行符)。
^:匹配字符串的开头。
$:匹配字符串的结尾。
*:匹配前面的字符或子表达式零次或多次。
+:匹配前面的字符或子表达式一次或多次。
?:匹配前面的字符或子表达式零次或一次。
{n}:匹配前面的字符或子表达式恰好n次。
{n,}:匹配前面的字符或子表达式至少n次。
{n,m}:匹配前面的字符或子表达式至少n次,但不超过m次。
字符类:
\d:匹配任意数字字符,等价于[0-9]。
\D:匹配任意非数字字符,等价于[^0-9]。
\s:匹配任意空白字符,包括空格、制表符和换行符等。
\S:匹配任意非空白字符。
\w:匹配任意单词字符,包括字母、数字和下划线等,等价于[a-zA-Z0-9_]。
\W:匹配任意非单词字符,等价于[^a-zA-Z0-9_]。
[...]:匹配字符类中的任意一个字符。
[^...]:匹配除字符类中的字符之外的任意一个字符。
分组和捕获:
(...):将括号内的表达式作为一个分组,可以对分组应用量词和其他操作。分组还会捕获匹配的子字符串,以便稍后引用。
\n:引用第n个分组的捕获内容(n为一个整数)。
(?:...):非捕获分组,将括号内的表达式作为一个分组,但不捕获匹配的子字符串。
肯定和否定前瞻:
(?=...):肯定前瞻,断言当前位置后面的内容匹配括号内的表达式。
(?!...):否定前瞻,断言当前位置后面的内容不匹配括号内的表达式。
替换中的特殊字符:
\g<n>:在替换字符串中,引用正则表达式中第n个分组的捕获内容。
了解这些基本的正则表达式语法后,您可以根据实际需求编写更复杂的正则表达式来匹配和处理字符串。以下是一些实际示例,帮助您更好地理解如何使用正则表达式:
匹配电子邮件地址:
python
代码
import re
pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b"
string = "Please send an email to info@example.com for more information."
match = re.search(pattern, string)
if match:
print("Email found:", match.group())
else:
print("No email found")
提取URL:
python
代码
import re
pattern = r"https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+"
string = "Visit our website at https://www.example.com for more details."
matches = re.findall(pattern, string)
print("URLs found:", matches)
验证密码强度(至少包含一个大写字母、一个小写字母、一个数字和一个特殊字符,长度至少为8个字符):
python
代码
import re
pattern = r"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$"
password = "P@ssw0rd123"
match = re.match(pattern, password)
if match:
print("Strong password")
else:
print("Weak password")
删除多余的空白字符:
python
代码
import re
pattern = r"\s+"
string = "Remove extra spaces and line breaks."
result = re.sub(pattern, " ", string)
print("Result:", result)
替换HTML标签:
python
代码
import re
pattern = r"<[^>]+>"
string = "<p>This is a <b>sample</b> HTML string.</p>"
result = re.sub(pattern, "", string)
print("Result:", result)
通过学习更多实例和练习,您可以更熟练地运用正则表达式来解决各种字符串处理问题。



声明本文内容来自网络,若涉及侵权,请联系我们删除! 投稿需知:请以word形式发送至邮箱18067275213@163.com
网站全新改版,所有页面和内容都换了,原来的网站该如何处理,因为原来的网站是企业站空间,没有网站数据,直接登陆就是后台,所以无法拷贝数据,现在一起用改版新网站,将域名指向新改版的,那原来的将都没有了,请问该怎么处理这样的问题!!万分感谢!!
如何购买本书呢,一看就是好东西
这些问题挺有意思的,真正的受教了!