如何实现自动记录百度搜索引擎爬虫访问到后台系统日志
要自动记录搜索引擎爬网程序对后台系统日志的访问,可以执行以下步骤:
标识要跟踪的百度搜索引擎爬网程序的用户代理字符串。您可以在网上找到主要搜索引擎的常用用户代理列表。
配置web服务器以将所有访问请求(包括用户代理字符串)记录到文件中。
编写脚本或使用现有工具监视访问日志文件,并提取与百度搜索引擎爬网程序的用户代理字符串匹配的记录。
将提取的记录存储在单独的日志文件或数据库中,以便进一步分析。
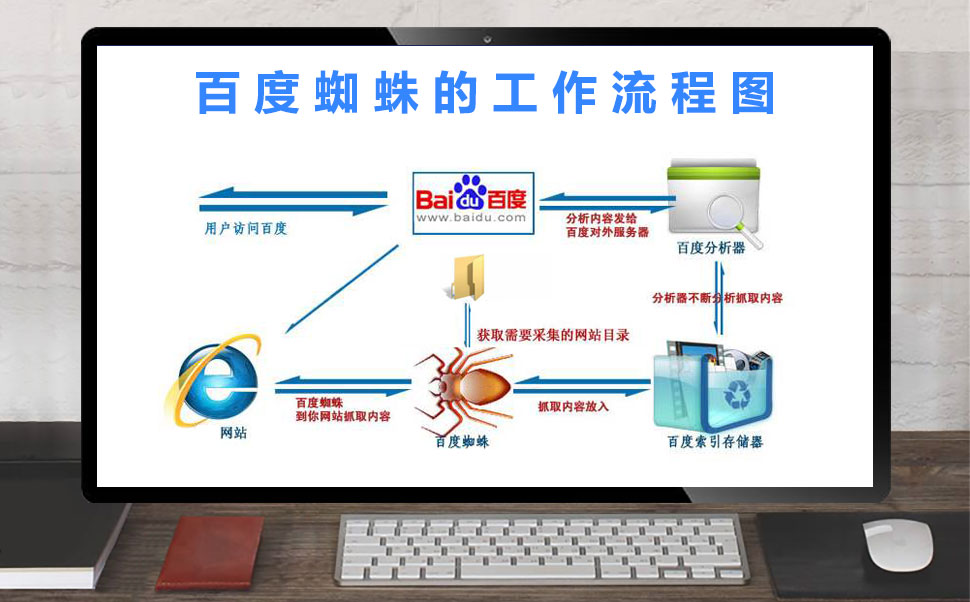
搜索引擎蜘蛛爬虫的原理是系统地浏览和索引互联网上的网页,以建立一个全面和最新的可搜索内容数据库。
以下是搜索引擎蜘蛛爬行器的工作原理:
爬虫首先从URL请求网站的根页面。
然后,它扫描页面的HTML源代码,以提取到站点上其他页面的链接,并按照这些链接对站点内的所有页面进行爬网和索引。
爬行器还查找到其他网站的外部链接,并跟踪这些链接来爬行和索引其他网站上的页面。
当爬虫爬行和索引页面时,它提取并存储元数据,如页面标题、描述和关键字,以帮助搜索引擎更好地理解每个页面的内容。
爬虫通常会定期重新访问以前已爬网的页面,以检查更新和更改,并将发现的任何新页面添加到其索引中。
然后,搜索引擎算法使用索引根据用户的搜索查询向用户提供相关的搜索结果。
总的来说,搜索引擎爬行器的原理是持续扫描和索引网页,为用户提供最相关和最新的搜索结果。
下面是一个使用Apache web服务器访问日志格式和grep命令提取百度蜘蛛记录的示例脚本:
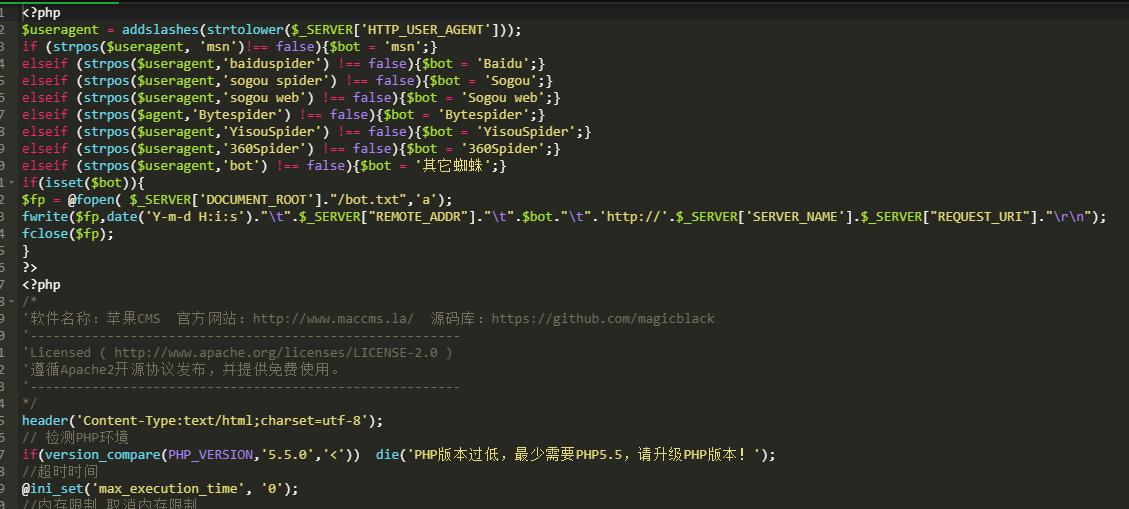
bash
#!/bin/bash
LOG_FILE=“/var/LOG/apache2/access.LOG”
SEARCH_AGENT=“百度蜘蛛”
OUTPUT_FILE=“/var/log/crawler_access.log”
grep“$SEARCH_AGENT”“$LOG_FILE”>>“$OUTPUT_FILE”
此脚本与我之前提供的脚本类似,但有一些更改。
首先,SEARCH_AGENT变量设置为“Baidubot”,以匹配百度搜索引擎爬虫使用的用户代理字符串。
其次,OUTPUT_FILE变量设置为“/var/log/bidubot_access.log”,以将提取的记录保存到/var/log目录中名为baidubot_access.log的文件中。
最后,可以使用cron作业或类似的调度程序定期运行脚本,以自动跟踪Baidubot对网站的访问。





声明本文内容来自网络,若涉及侵权,请联系我们删除! 投稿需知:请以word形式发送至邮箱18067275213@163.com
刚看了您的演讲照片,确实发福了,不过这说明心态好啊 39岁年龄是不小,不过仍然年轻,应当是出成就的时候啊,而且任何时候,只要保持心态不老,我们就会永葆活力!
同上。阻挡是指收到后归类到“垃圾邮件”,还是直接阻止发出
百度站长工具里11月3日有发了个:“织梦、帝国、WordPress用户MIP改造捷径,搜索优待快速到手”的消息,看了消息里推荐的视频,没看懂,都是技术改造内容……然后今天看了文章中:“响应式设计与MIP是否有矛盾”这个部分,而我目前的这个wordpress站长,移动端就是响应式,并未设置独立移动端URL,而对于给的解决方案:”响应式设计目前的做法还是要把MIP和移动版做成两套URL,和AMP一样”,关于这点有点疑问,那意思是如果为了实现MIP功能,就得设置一套独立的移动端URL?同时,保留原有的PC端URL用于自适应响应展示?那不是又矛盾了吗?╮(╯▽╰)╭求解,谢谢!不是“设置一套独立的移动端URL”。而是一套独立的MIP专用URL。原来响应式设计还是适用于PC端和移动端,MIP是一个单独的特殊的移动端。感谢回复!可能我概念还没理解清楚,我再了解下,谢谢。
一直规规矩矩的做SEO,做内容运营,从不敢违规,但新站上线快3个月,百度收录忽然下降了20%,不知道啥原因,其他搜索引擎没问题。
不错,挺好。
是啊,我要第一个报名,呵呵。
另外,请你具体说一下,怎么样支持你们,把这样一个有历史使命的排名做上去。我不懂SEO,但是想出一份力,是去google上搜索Tibet,然后点我们的目标网站这样吗?
哥,应该去5g开个帖子,那里淘宝的人较多
太有才了 这招管用的很我也学习啦 呵呵
楼上的,被DOMZ收录,也只能分到那个目录的PR的一小部分了,不可能太多的提升的。升PR要质量还要数量。被DOMZ收录很难啊,恭喜啊!