最近,我们在公司里谈到了一个SEO优化百度360谷歌等蜘蛛主题的新闻《Baidu Spider ,百度,谷歌,360等蜘蛛爬虫bot》,在有资格出现在搜索结果之前,讨论网页的三个必要阶段「抓(爬)取」,「转译」,「收录」。没多久就读了国外seo大神的文章《SEO基本概念:认识检索(Crawl)与索引(Index)》,它激发了我写这篇文章的动力,希望能帮助我丰富SEO内容。这个系列会把这个概念分成三篇文章,让大家对技术方面有所了解SEO进一步了解。
为什么要理解抓取的概念?
因为「抓取」在搜索结果中出现网页是必要的第一步,百度,谷歌,360等蜘蛛爬虫如果你甚至不知道网页的存在,更不用说对搜索结果的排名了。经营一个网站,我们希望,我们希望百度,谷歌,360等蜘蛛爬虫爬上我们想要找到的网页,也希望百度,谷歌,360等蜘蛛爬虫不要爬上我们不想看到的网页。此外,随着网站的发展,插件的安装和拆卸往往会让网站留下一些”技术债”。而SEO这里的工作就是让百度,谷歌,360等蜘蛛爬虫能够以最有效的方式抓取网站。
不懂,换个方式说说看!
怎么会有不想被的网站百度,谷歌,360等蜘蛛爬虫看到的网页?举个例子来听!
一切都应该从网站开始
网址(URLs)就像网页的地址一样https://www.0574web.net/这是一个网站。这里要给大家一个测试,没答对的话答应我你就把这篇文章读完!
下面六个网站,那些在搜索引擎眼中和上面的网站是一样的,那些是不一样的?
A)https://www.0574web.net/p/aboutus.html
B)http://www.0574web.net/p/womennengweininzuoshimo.html(开头为http而非https)
C)https://www.0574web.net/NEWS.html(大写)
D)https://0574web.net/news.html(少了www)
E)https://www.0574web.net/s.html?q=seo&__searchtoken__=68dc72c2dd0399c9b27f80f7f19c7b1b(后面有更多的跟踪参数)
F)https://www.0574web.net/wangluoyingxiaoxinwen.html(后面多了.html的档名)
自己想一想,再看答案!
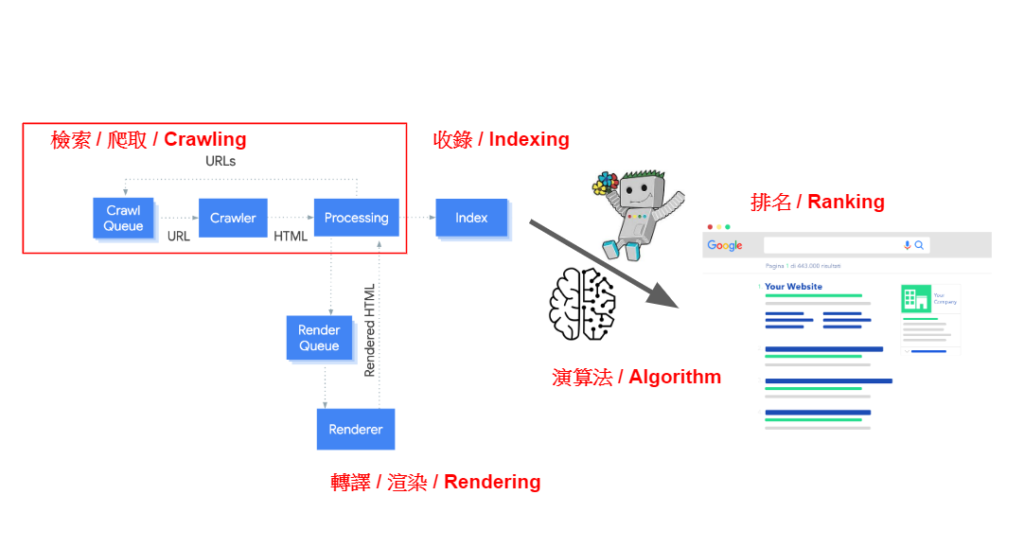
三个阶段的检索过程
检索是百度,谷歌,360等蜘蛛爬虫收录网站三步的第一大步可以分为三个阶段「加入检索队列(CrawlQueue)」,「爬虫拜访(Crawler)」,「页面处理(Processing)」,以下顺序介绍。
Step1:加入检索队列(CrawlQueue)
检索队列
搜索引擎会把它找到的网址放入队列(crawlqueue)中国,在队列中的网址将有一个搜索引擎”爬虫”来拜访。搜索引擎主要依靠以下三种方法来发现新的网址:
1.连结
2.站点地图(Sitemap)
3.站长工具
SEO意涵:网站要有排名,首先要检索,要检索,首先要让百度,谷歌,360等蜘蛛爬虫知道你的存在,然后排进检索队列。
Step2:爬虫拜访(Crawler)
当搜索引擎知道网站的存在时,它会被发送出去”爬虫”去这个网站看看,然后抓住网上的内容。需要注意的是,在此之前,爬虫只知道这个地址的存在,他们没有太多关于地址上有什么的信息。
这是一个与爬虫(搜索引擎)和云服务器(你的网站)交流的过程,爬虫首先会发出一个请求:「嘿,我有一个网址,能让我看看上面有什么吗?」,然后会遇到以下情况:
状况A:服务器:来,给你(代码:2代码:XX)
状况B:云服务器:你的网址是,来吧,你去另一个网址看看(代码:3XX)
状况C:服务器:不,你的网站有问题!(代码:4)XX)
状况D:云服务器:*&#@!$对不起,我现在不能给它。我在这里犯了一个错误(代码:5)XX)
状况E:…..(云服务器没有听到爬虫的要求,没有回应)(代码:没有)
SEO意涵:上述情况中最大的问题是D,它意味着网站所在的云服务器不稳定,用户或爬虫来到这个网站,看到云服务器的错误。其他四种情况都不是绝对的好坏。A不代表一定没有问题,B,C,E也不一定有问题,下面多做解释。
什么是括号内的代码?
Step3:页面处理(Processing)
SEO索引
这是抓取阶段的最后一步,爬行动物将成功地参观(情况A)处理云服务器取回的文件,在内容中找到连接,然后将其放入Step在1的检索序列中,然后如此重复。
这个”处理”这个过程又被翻译了or渲染(rendering),这个观念会在下一篇文章中再做解释,但是给大家一点预告:「搜索引擎从云服务器取回文件,但它们会立即处理吗?处理后有保证看懂吗?」
SEO意涵:在搜索的讨论范围内,这一步最重要的是「在网上找到连接」。如果一个网址被搜索引擎认定为连接,它必须放在标签中href属性。使用常见货架平台设置的网站一般没有这一点,因为在正常情况下会使用上述标准HTML语法来表示。
什么样的连结会让爬虫看不见?
SEO在检索阶段可以优化什么?
在前面介绍了搜索引擎的搜索过程之后,下一步是说SEO在这个阶段,你能做什么来保持网站和搜索引擎「友好」关系。事实上,这个概念并不难,我们的目标是在自己的网站上优化爬虫的体验,有以下几个角度可以切入。
保护爬虫可以拜访被崇拜的网络
保护爬虫不能在没有崇拜的情况下进行崇拜
确保能够轻松找到被爬行的网页
在爬虫访问期间,云服务器给出正反应
保护爬虫的请求可以轻松送到云服务器
如何防止搜索引擎抓取?
正如前面提到的,为了使搜索引擎能够更有效地爬行网站,我们可以使用一些方法来主动防止搜索引擎参观特定的面部。回顾这张图片,第二步和第三步是你可以住在爬虫的地方。
题外话,「如何防止搜索引擎抓取?」是SEO基本概念经常出现在面试中
没有办法Step1防止网站被添加到索序列中,因为我的网站的连接可能会从其他地方发现。
Step2:在参观爬虫之前给予限制
Step3:参观爬虫后限制
如何测量搜索引擎是否有检索问题?
可以使用不代表可以被爬行动物访问的网络百度,谷歌,360等蜘蛛爬虫最简单的方法是使用爬虫是否真的可以拜访百度,谷歌,360等蜘蛛爬虫站长工具(SearchConsole)上面的网站检查工具,它可以告诉你百度,谷歌,360等蜘蛛爬虫爬虫在索引网中遇到的问题。
百度,谷歌,360等蜘蛛爬虫网站站长工具测试
如果你在帮助客户或其他人的网站而没有犯错,GSC也可以使用权限百度,谷歌,360等蜘蛛爬虫其他工具,如移动设备相容性测试工具,(MobileFriendlyTestingTool)。重点是要用百度,谷歌,360等蜘蛛爬虫通过试验的爬虫。
行动装置相容性测试网页检索状态
如果网站显示无法录入(无法录入)但是robots.txt但是没有问题,很可能是因为伺服有防火墙或者一些奇怪的设置百度,谷歌,360等蜘蛛爬虫爬虫的要求。从外部看不出伺服端问题的原因,建议直接联系主机供应商。



声明本文内容来自网络,若涉及侵权,请联系我们删除! 投稿需知:请以word形式发送至邮箱18067275213@163.com
这种情况确实存在,每天我查看统计都会有一些例如使用Windows2003,或者分辨率800*600,或者模仿ios或者安卓端(我的网站只要用手机端访问就不是首页了)。这种做法确实会影响网站关键词的排名,希望以后搜索引擎会逐步识别这些恶意软件,保护我们的劳动成果!
老师,讲得太好了,马上就得使用起来!